This passage will lead you through the whole process of the implementation of image classification tasks on CIFAR-10 and also explain some confusing parts for beginners in detail. Besides, I also put down what I've learned in the middle and hope you will at least grasp how you should build up the whole pipeline of conv net at last.
1 | #notebook setup |
The autoreload extension is already loaded. To reload it, use:
%reload_ext autoreloadAnd also some useful function:
1 | def show_images(imgs): |
First we need to download the data if needed. And then preprocess as following:
- 4 pixels padding and random cropping
- flipping randomly
- normalize
The intuition behind them are explained here:
This is referred to as data augmentation. By applying transformations to the training data, you're adding synthetic data points. This exposes the model to additional variations without the cost of collecting and annotating more data. This can have the effect of reducing overfitting and improving the model's ability to generalize.
The intuition behind flipping an image is that an object should be equally recognizable as its mirror image. Note that horizontal flipping is the type of flipping often used. Vertical flipping doesn't always make sense but this depends on the data.
The idea behind cropping is that to reduce the contribution of the background in the CNNs decision. That's useful if you have labels for locating where your object is. This lets you use surrounding regions as negative examples and building a better detector. Random cropping can also act as a regularizer and base your classification on the presence of parts of the object instead of focusing everything on a very distinct feature that may not always be present.
And a very approaching idea on random cropping:
I think random cropping also associate a broader range of spatial activation statistics with a certain class label and thus makes the algorithm more robust.
Some tips here: 1. just mentioned CIFAR in PyTorch will load all data into memory at the beginning, not too large. 2. T.ToTensor will convert img in the range [0,255] to that in [0,1]. Some codes Normalize them using (0.5,0.5,0.5) to rescale it to range(-1,1) after ToTensor operation.
1 | # size of the image dataset N * 32 * 32 * 3 |
Files already downloaded and verified
Files already downloaded and verified
Files already downloaded and verified
Then we will import Resnet-18 to train our dataset on the training data. These two models use different architecture, one with basic block and the other with one called bottleneck. I specifically choose these two different sorts of models with relatively less layers due to the limit of the computational resources.
1 | from resnet import Resnet18 |
1 | use_cuda = torch.cuda.is_available() |
I use total 200 epoches. Thanks to the GPU, the training time for each epoch is merely 1.25 minutes, which is a drastically cut compared to almost 50 minutes via CPU. Then, I will try to visualise the whole training process and see what happens in the process.
1 | import pickle |
1 | plt.style.use('seaborn-white') |
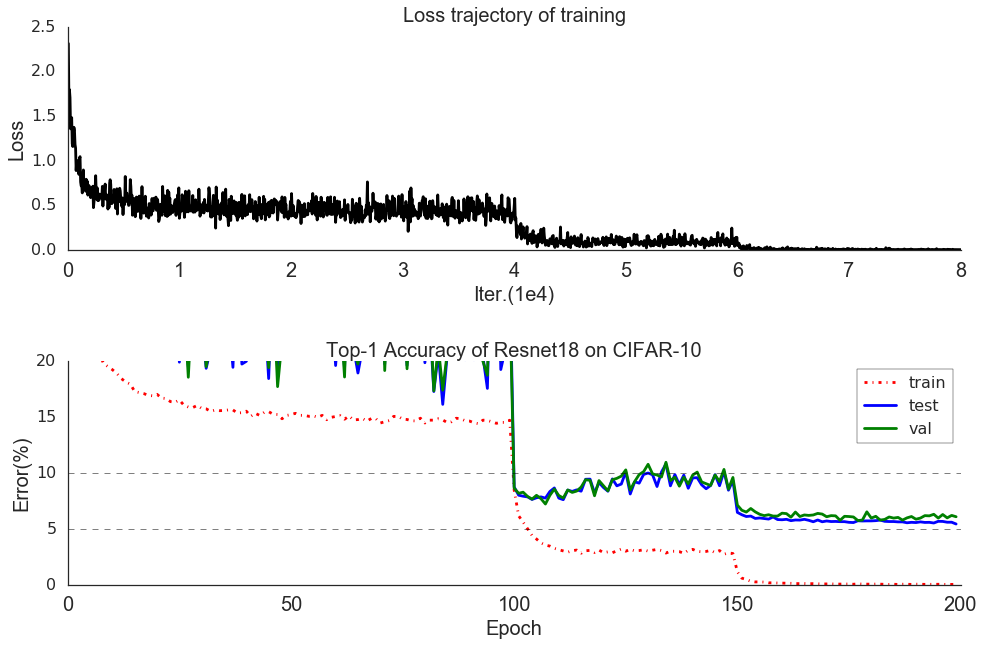
There are two things we need to pay attention to:
The training process stagnates quickly after we adjust the learning rate, which indicates we can actually cut some training time after the adjustment and proceed without the loss of performance.
We can see that the both loss and error drop drastically after we decrease the learning rate by a factor of 0.1, it may tell us we can further improve the performance by adding more lr decreasing stage. Although the marginal gain is apparently decreasing as we can expect.
And interestingly, the model does not show a evident tendency to overfit the data after the second time we adjust the learning rate. Maybe part of the reason is the error rate is very close to zero in the last stage. So the classifier has no further space to improve and overfit the data. It also give use some hints that maybe we can increase the weight decay to make our network better!
And next I will shed some light on the resnet-50 without actually running it.
The resnet-50 or more layers like 101 or 152 use a different architecture called Bottleneck. The intuition behind this is more of practical consideration. It works better than just stacking layers in the BasicBlock from 2 to 3. We can see that part of the reason is that the bottleneck structure cuts some parameters due to the 1x1 conv layer, which first reduces the input dimension and then restores the output dimension, and makes network deeper while keeping the time complexity the same as the basicblock of 2-layer version. As a result, the degradation problem will be less severe compared with one using basicblock to have 50 or more layers as we can expect.
